GLM-5.2
GLM-5.2 is the flagship model built for the long-task era, featuring a truly usable 1M context window and 128K max output tokens. With GLM-5.2, developers can complete the entire development chain from requirements to deployable artifacts in a single continuous task. GLM-5.2 keeps engineering standards reliable across extended sessions.
Feedback
😢 Every free AI generation costs us real GPU money. We pay out of pocket to keep this free for you.
💎 Upgrade to Pro and unlock:
- ✓HD Download
- ✓No Watermark
- ✓Unlimited Generations
All Tools
Discover our comprehensive AI-powered animation toolkit

Seedance2.0
The Future of AI Video Is Here.

Free AI Image
Truly Free AI Image Generator

Happy Horse 1.1

Gemini Omni
Gemini Omni Video Generator

Seedance 2.1
The Future of AI Video Is Here.

Veo3.1
Create Stunning Videos with Veo3.1

Kling 3.0
Next-Gen AI Video Generator
Grok Video Generator
Create Videos from Text or Images with AI
Why Choose GLM-5.2
GLM-5.2 is a flagship base model engineered for the long-task era, delivering a solid 1M lossless context and 128K max output tokens. GLM-5.2 has been reinforced for long-range coding agent scenarios, covering large-scale implementation, automated research, and performance optimization. With GLM-5.2, engineering standards remain reliable across extended sessions, and GLM-5.2 can carry complete project-level contexts within a single reasoning chain.
- 1M ContextGLM-5.2 supports a truly usable 1M context window for project-level engineering and long-running tasks.
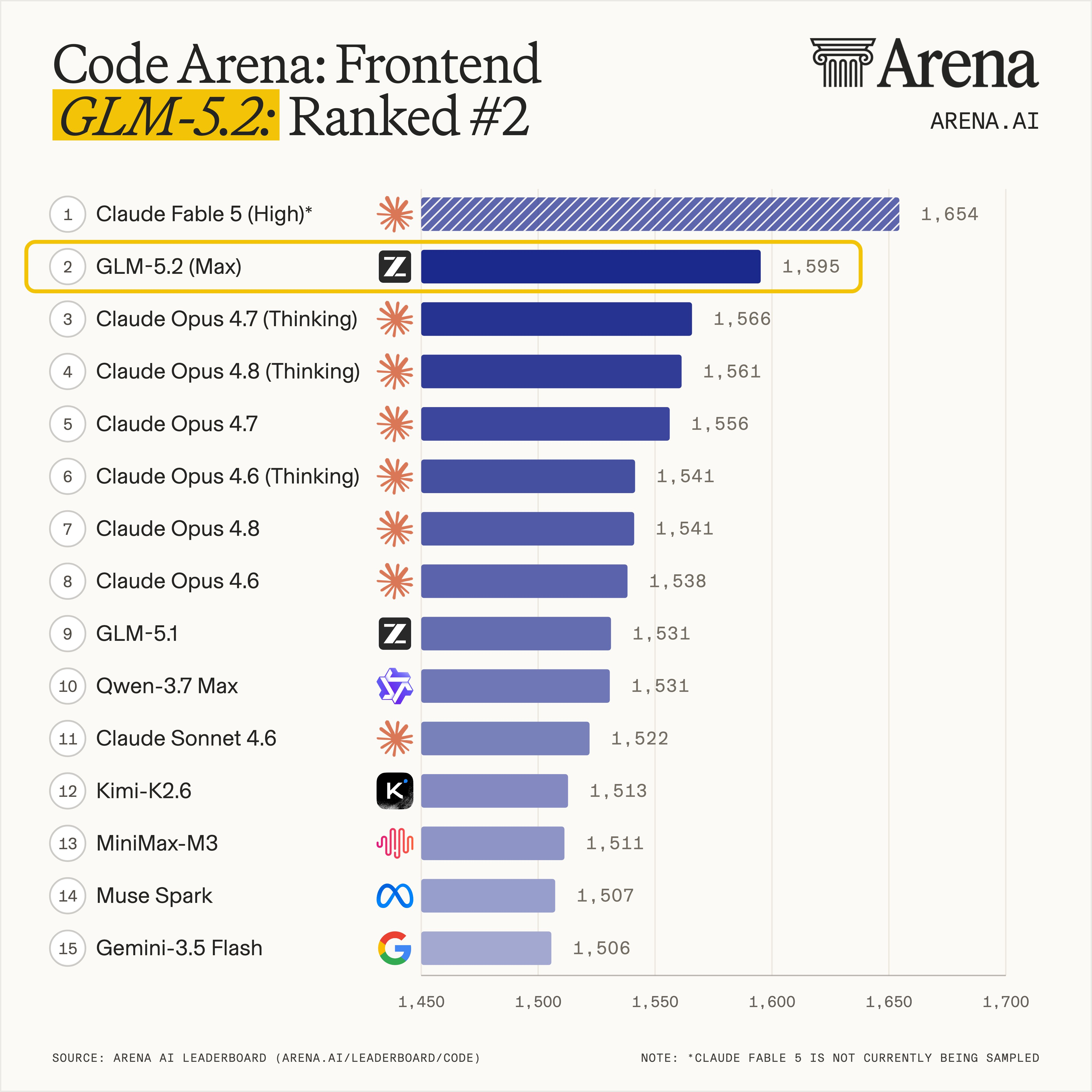
- Coding ExcellenceGLM-5.2 maintains open-source SOTA on mainstream coding benchmarks and ranks first globally on Code Arena among available models.
- Engineering ComplianceGLM-5.2 follows production-grade engineering standards reliably, including code style, architecture boundaries, and dependency constraints.
How to Use GLM-5.2
Get started with GLM-5.2 in three straightforward steps for your development and video creation projects.
GLM-5.2 Features
GLM-5.2 delivers multiple thinking modes, streaming output, function call support, context caching, structured output, and MCP integration for comprehensive development workflows.
Thinking Modes
GLM-5.2 provides multiple thinking modes covering different task requirements and complexity levels.
Streaming Output
GLM-5.2 supports real-time streaming responses for improved interactive user experiences.
Function Call
GLM-5.2 offers powerful tool-calling capabilities, supporting integration with various external tools and services.
Context Caching
GLM-5.2 implements intelligent caching mechanisms to optimize long-conversation performance and reduce latency.
Structured Output
GLM-5.2 supports JSON and other structured format outputs for seamless system integration and data processing.
MCP Integration
GLM-5.2 can flexibly call external MCP tools and data sources to extend application scenarios and workflows.
GLM-5.2 — FAQ
Common questions and answers about GLM-5.2.
What is GLM-5.2?
GLM-5.2 is a flagship base model built for the long-task era, supporting a truly usable 1M context and 128K max output tokens for project-level engineering.
What can GLM-5.2 do?
GLM-5.2 handles project-level engineering, long-range refactoring, mobile real-device debugging, mini-program development, mini-game development, and research replication.
How fast is GLM-5.2?
GLM-5.2 processes long-range tasks efficiently with streaming output and context caching for optimized performance across extended sessions.
Is GLM-5.2 good at coding?
GLM-5.2 maintains open-source SOTA on mainstream coding benchmarks and ranks first globally on Code Arena among available models, comparable to Claude Opus 4.8.
What context length does GLM-5.2 support?
GLM-5.2 supports a solid 1M lossless context window, capable of handling project-level engineering contexts with stable performance.
What projects work with GLM-5.2?
GLM-5.2 is ideal for web development, mobile apps, WeChat mini-programs, mini-games, scientific research code replication, and coding-to-video workflows.
Try GLM-5.2 Today
Start building with GLM-5.2 and experience the power of a truly usable 1M context for your development projects.